AI-related bots in robots.txt of media sites#
This project aims to look for AI-related bots in robots.txt from media sites. The repository is hosted at https://codeberg.org/penguinsfly/robots-txt-ai-bots.
This is due to the rise of ChatGPT (and generally generative AI), and people’s worry about companies scraping their websites for training large language models.
The list of media sites is obtained from mediabiasfactcheck.com, whose bias/fact-check categories are also used to compare with the related bots.
Lastly, robots.txt records from the Wayback Machine of a few selected sites are collected on a weekly basis to further inspect when sites adopt these bots.
Note: a similar project has been done at https://originality.ai/ai-bot-blocking since around August. I picked up this project during one of my free weekends at the end of October out of curiosity and didn’t do much searching.
Requirements#
Generally:
python&jupyterlab, for scraping and visualizing dataaria2c, for downloading fileszstd, for (de)compressing data files
To install dependencies (after the above are satisfied):
pip install requirements.txt
Additionally, I also use rawgraphs for one of the visualization plots (online).
Data acquisition#
Sites from mediabiasfactcheck and their categories#
The categories from mediabiasfactcheck.com includes:
left
leftcenter
center
right-center
right
fake-news
conspiracy
pro-science
satire
Some media sites share the same host url (e.g. https://host.com/A, https://host.com/B) which would end up merging categories (e.g. if A is left and B is center then host.com would be categorized as left | center).
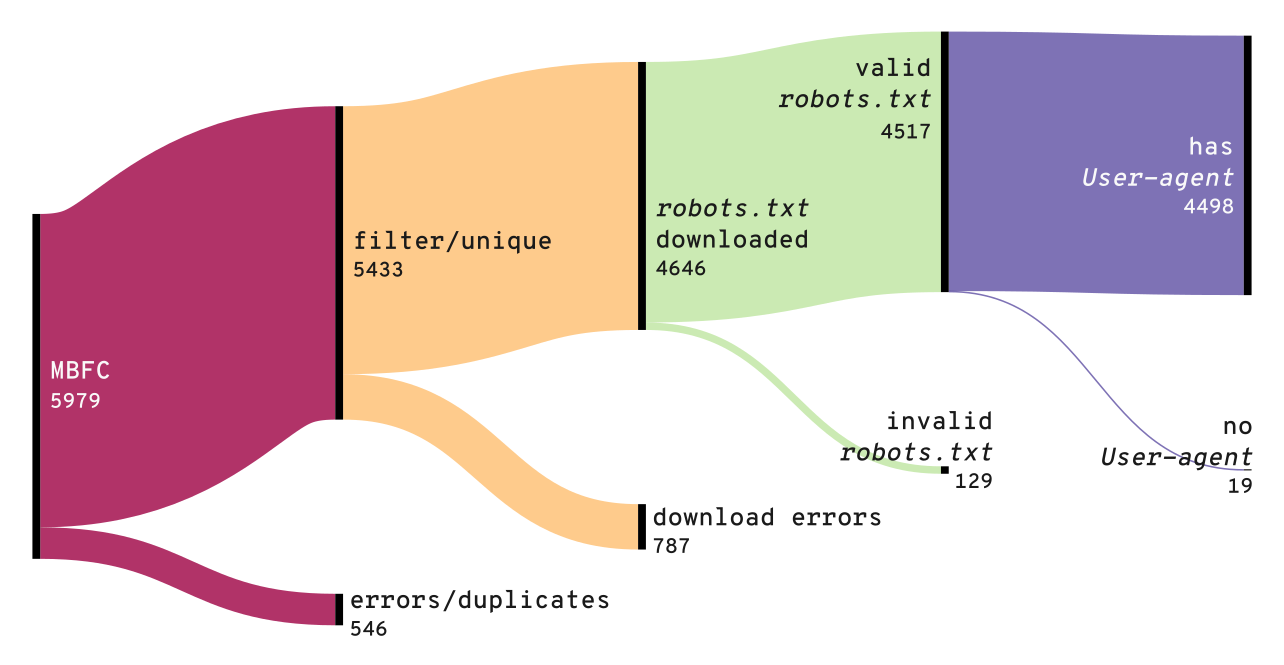
In terms of stats:
5979 sites from mediabiasfactcheck.com originally
5433 / 5979 sites, after filtering out parsing issues and duplicated host URLs
4646 / 5433 sites, with
robots.txtdownloaded4517 / 4646 sites, which seem to be valid
robots.txt, i.e. have the following fields:Sitemap:,User-agent:,Disallow:,Allow:,Crawl-delay:
4498 / 4517 sites, whose
robots.txthasUser-agent:These end up being analyzed more closely
For more information, see:
data/mbfc/sites.csvdata/robotstxt-20231029.tar.zst(compressed fromdata/robotstxt)
This was run to compress the folder containing the robots.txt
cd data
ZSTD_NBTHREADS=6 tar -I 'zstd --ultra -22' -cf robotstxt-20231029.tar.zst robotstxt
Selections for Wayback machine#
The following sites are selected to further collect robots.txt records from the Wayback Machine, maximum frequency of collection is every week starting from beginning of 2023.
https://abc12.com
https://arstechnica.com
https://cell.com
https://www.cnn.com
https://foxbaltimore.com
https://mynbc5.com
https://www.nationalgeographic.com
https://www.npr.org
https://www.nytimes.com
https://www.reuters.com
https://science.org
https://www.theonion.com
https://the-sun.com
https://www.thesun.co.uk
https://www.vice.com
https://www.vox.com
https://www.who.int
https://www.zdnet.com
https://joerogan.com
For more information, see:
data/robots-wayback-20231102.tar.zst(compressed fromdata/robots-wayback)
This was run to compress the folder containing the robots.txt obtained from the Wayback machine.
cd data
ZSTD_NBTHREADS=6 tar -I 'zstd --ultra -22' -cf robots-wayback-20231102.tar.zst robots-wayback
Visualization#
See notebooks/D-visualize.ipynb for details to visualize the processed data from data/proc.
The resulting figures are saved in figures:
figures/mbfc-sites: general visualization of statistics of ~4500 sitesfigures/wayback: ~19 sites selected for wayback machine